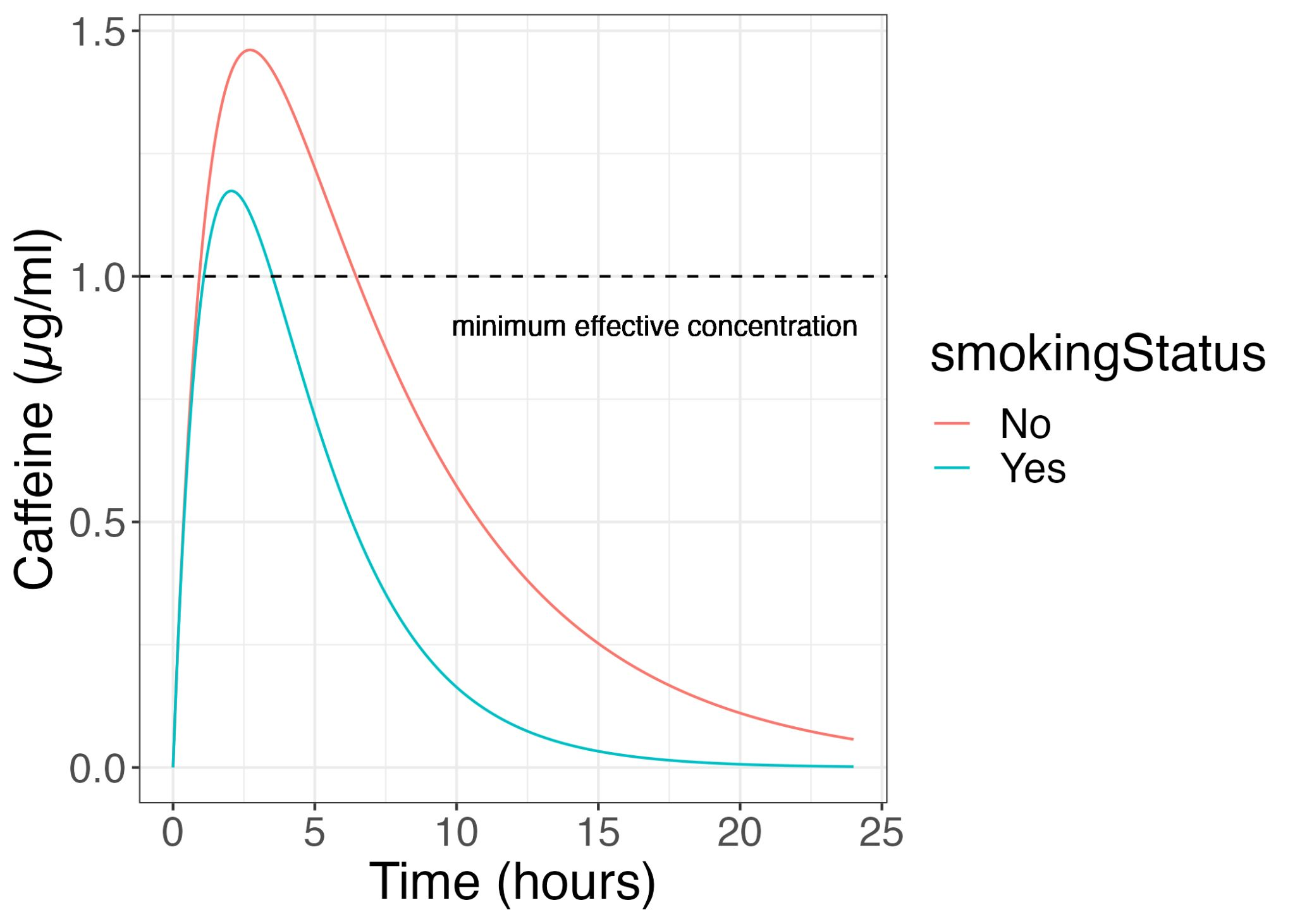
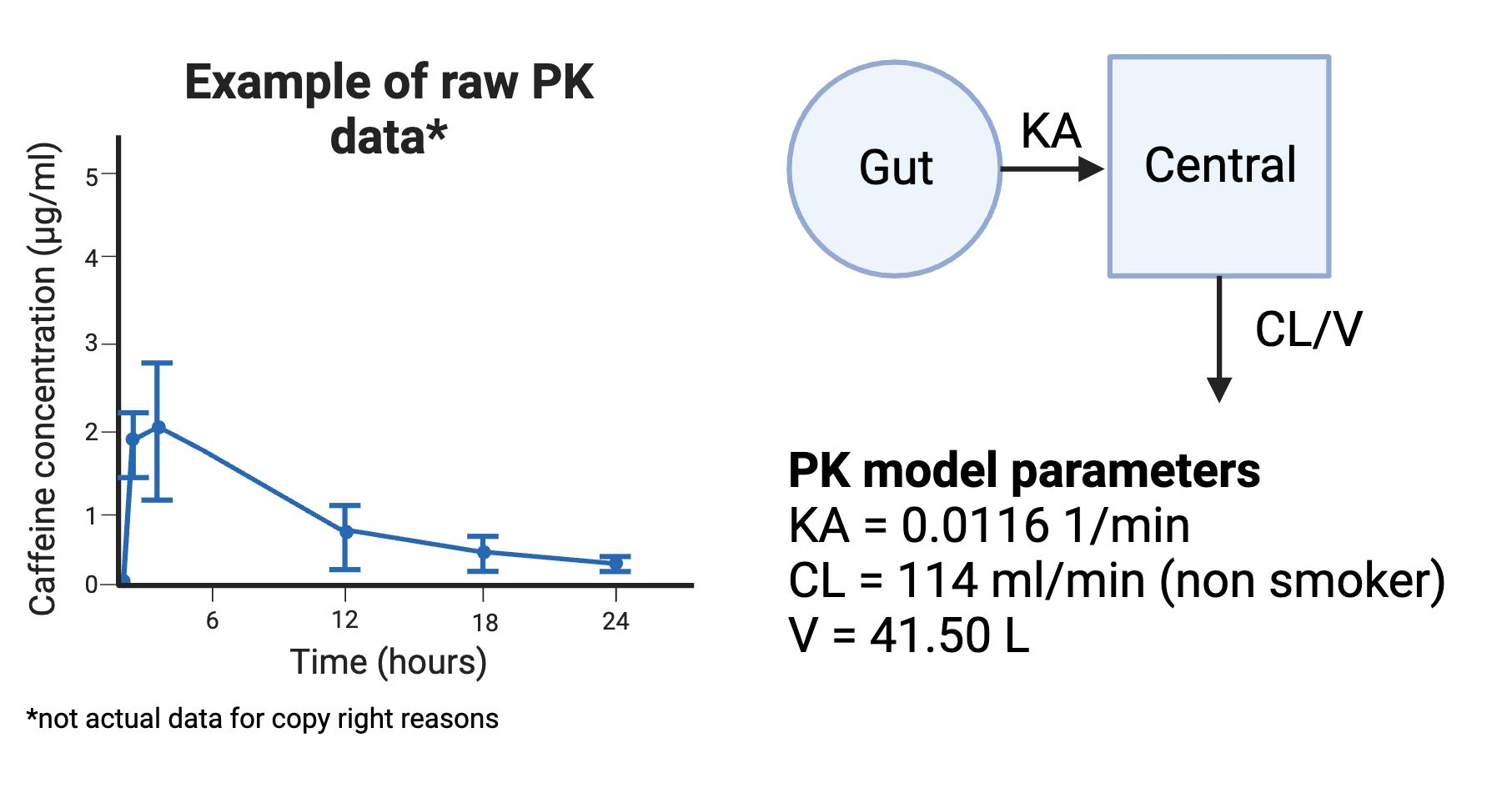
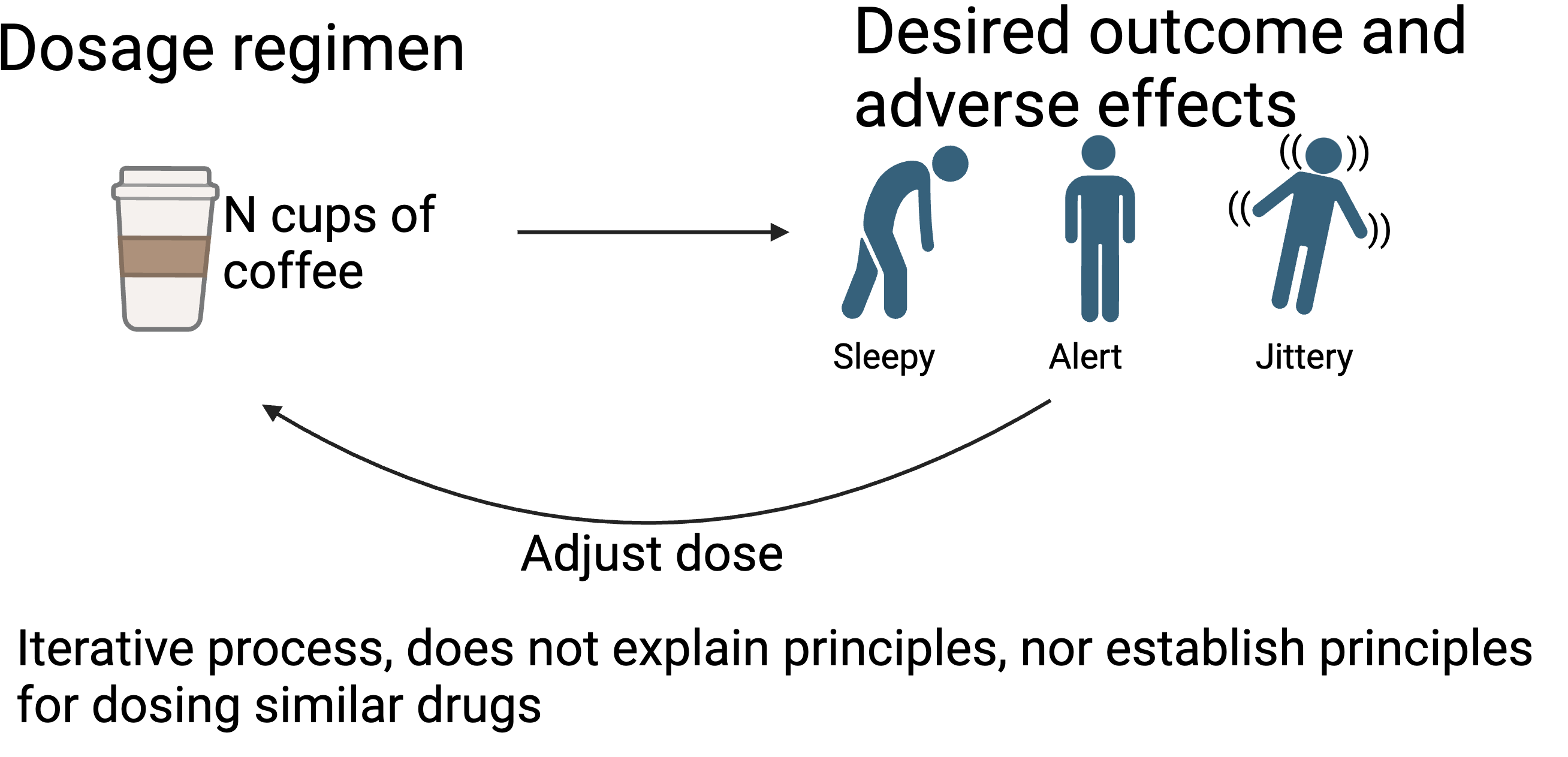
Thank you all for staying with me throughout this series! It has been fun sharing about my field with all of you!
Over the past few weeks we have played with, and discussed the principles behind the coffee simulator, and how it was made. In summary, we have covered, (each point corresponds to a post, which you can find in my profile)
- How modeling and simulation is useful to create rules for understanding efficacy and/or toxicity
- What kind of data is needed to build such a model
- How to build your own simulation using PKPDsim in R
- How to do rigorous testing for which factors influence variability in a drug profile the most
I had a lot of fun creating the app and discussing it with all of you! As our last topic for today, I wanted to share some real world examples too of how PK has been used.
- Optimizing drug dosing for drug with narrow therapeutic windows
Drugs such as vancomycin (a potent antibiotic for severe infections) have a narrow therapeutic window but very variable PK based on a patient’s kidney function. Using PK models, we can help to recommend the appropriate vancomycin dosing such that patients can still be cured of their infection while reducing their chances of serious side effects such as hearing loss. An increasing number of hospitals are engaging pharmacometricians to help them design such dosing algorithms for their patient populations. Here is an example of an open source one https://pubmed.ncbi.nlm.nih.gov/35353046/
- Understand site of action bioavailability
Very often PK studies are done using plasma drug concentrations. However, plasma drug concentrations may not always be reflective of the actual amount of drug the disease site needs to receive. This is often a problem when we need to treat organs that are hard for drugs to penetrate, such as the brain, or, when the disease site does not have good blood flow, e.g. solid cancer tumors or tuberculosis lesions. Getting drug concentrations from these sites are often a lot trickier and more sparsely sampled. PK models can help us to better understand this drug penetration into the target site and simulate the drug dose needed for adequate exposure at the site of action.
Natasha Strydom has a nice paper detailing how to study drug penetration into TB lesions using a PK-PD approach. https://pubmed.ncbi.nlm.nih.gov/30939136/ This paper also has a RShiny app to play with! http://saviclab.org/tb-lesion/
- Tailoring drug dosing for special populations
Special populations often consist of people who are not as easily studied, such as pregnant women or children. However, we cannot simply assume that such populations will handle drugs the same way as our general healthy adult population.
This study by Jordan Brooks shows how we can use popPK to better dose tacrolimus for our paediatric cancer patients. https://pubmed.ncbi.nlm.nih.gov/34950026/
- Translating preclinical observations to clinical outcomes to help with dose recommendations
Understanding drug PK in different preclinical models such as mice, coupled with drug efficacy in these models can be used to determine an exposure-response relationship that is translatable from these mouse models to human trial outcomes.
Here is an example https://erj.ersjournals.com/content/early/2023/06/08/13993003.00165-2023
There are many other applications out there! Feel free to share your own applications or interests too in the comments. Now its time for me to take a quick break and relax with a cup of coffee.